안녕하세요, 솬씨티입니다!
드디어 머신러닝 첫 게시글을 올리게 되네요
감격의 순간...
앞으로 배울 것도 해야할 일도 많지만
꾸준히 연재해보겠습니다!
오늘은 머신러닝의 기본 개념인
의사결정나무(Decision Tree)에 대해 다뤄보겠습니다.
사실 회사에서 요즘 Optimized Bucket Project에
Involve 되면서 더 합리적인 의사결정 모델이
뭐가 있을까 공부 끝에..
크게 어려운 개념은 아니지만
이 모든게 최적의 의사결정을 위한
하나의 알고리즘이라 생각하고..
그럼 시작하겠습니다!
모델 소개
한마디로 쉽게 말씀드리자면,
의사결정 나무는 대량의 데이터를
① 일정한 패턴으로 분류하고,
② 예측 가능한 규칙의 조합으로 큰 집단을 쪼개어서
③ 데이터에 대한 분류 및 예측하는 데 쓰이는 기법!
이라고 할 수 있습니다.

위 예시는 이진 분류(Binary Classification) 문제입니다.
'Play >0' & 'Don't Play < 0' 이 두 조건을 만족하면
Play를 하는 과정을 나타냅니다.
그럼 도식대로 날씨가 맑고(Sunny),
습도(Humidity) 가 70 이하이어야
Play가 이루어집니다.
또한 날씨가 Overcast 상태이거나,
비가 오는 동시에 (rain), 바람이 안불어야 (Not windy)
Play가 이루어집니다.
결국 Root node (맨 상위층 Node)에서
여러개의 Intermediate node로 나누어지고
결국 Terminal Node까지 나누어지게 됩니다.
여기서 중요한건
각 terminal node에 속하는 데이터의 개수를 합하면
root node의 데이터수와 일치한다는 것입니다.
(ex. 왼쪽에서 첫번째 terminal node와 두번째 terminal node의 데이터 합이
바로 상위층의 intermediate node 데이터 합과 일치하는 원리입니다.
그럼 남은 node의 총합은 여러분도 하실 수 있겠죠?)
이는 곧 terminal node 간에 교집합이 없다는 뜻입니다.
불순도/불확실성
그럼 의사결정 나무를 어떤 기준으로 분류하느냐
이것이 문제일 것입니다.
이는
(1) 순도(homogeneity)의 증가 or
(2) 불순도(impurity)나 불확실성(uncertainty)의 감소
의 방향으로 학습을 진행시켜야 합니다.
쉽게 말씀드려서,
순도의 증가는 곧 '다양성이 감소'된다는 뜻입니다.
'순수한 상태'는 곧,
'모든 데이터가 같은 클래스에 할당된 상태'라 할 수 있습니다.
[순도 증가 / 불확실성 감소]를 두고
정보이론에서는 정보획득(information gain)이라고 합니다.

먼저 설명드릴 지표는 엔트로피(entropy)입니다.
m개의 레코드가 속하는 A영역에 대한 엔트로피는
아래와 같은 식으로 정의됩니다.
(Pk=A영역에 속하는 레코드 가운데 k 범주에 속하는 레코드의 비율)

이 식을 바탕으로 검은색 박스로 둘러쌓인
A 영역의 엔트로피를 구해보겠습니다.
전체 16개(m=16) 중에
빨간색 동그라미(범주=1)는 10개, 파란색(범주=2)은 6개이군요.
그럼 A 영역의 엔트로피는 다음과 같습니다.
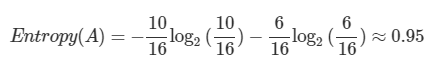
여기서 A 영역에 검은 점선을 그어
두 개의 부분집합(R1, R2)으로 분할한다고 가정합니다.
두 개 이상 영역에 대한 엔트로피 공식은 아래 식과 같습니다.
이 공식에 의해 A 영역의 엔트로피를 아래와 같이 각각 구할 수 있습니다.
(Ri=분할 전 레코드 가운데 분할 후 i 영역에 속하는 레코드의 비율)

그럼 분기 전과 분기 후의 엔트로피를 비교해봅시다.
분기 전 엔트로피 0.95
분할 후 엔트로피 0.75
0.2만큼 엔트로피 감소한 걸로 봐서
의사결정나무 모델은 분할한 것이 분할 전보다 낫다는 판단 하에
데이터를 두 개의 부분집합으로 나누게 됩니다.
불확실성 감소는 즉 순도 증가를 뜻하며,
순도의 증가는 정보의 획득을 뜻하니까요!
다시 한번 말씀드리지만 의사결정나무는
각 영역의 순도(homogeneity)가 증가/불확실성(엔트로피)가
최대한 감소하도록 하는 방향으로 학습을 진행합니다.
모델 학습
의사결정나무의 학습 과정은
입력 변수 영역을 두 개로 구분하는
(1) 재귀적 분기(recursive partitioning)와
디테일하게 분류된 terminal node를
영역 통합하는 (2) 가지치기(pruning)
두 가지 과정으로 나누어집니다.
특별히 지금 다니는 회사의 데이터를
활용하여 학습해 보겠습니다.

아래와 같이 16개 Partner 대상으로
Impressions, Revenue, KR or Global 를 조사한 데이터 입니다.
이를 토대로 Impressions과 Revenue를 설명변수 (X),
"KR or Global" 여부를 종속변수 (Y)로 하는
분류 나무 모델을 학습시켜 보겠습니다.
우선 이를 한 변수 기준(위 테이블은 Revenue)으로 정렬합니다.
그리고 분기 후의 엔트로피를 구하고
분기 전과 비교해 정보획득을 조사합니다.
정보 획득 = 0.95-0.75 = 0.2

예시는 이해하기 좋게 위 사례 수치와 같답니다 ^_^

그러면 위 엔트로피 식 안에 있는 log로 인해
엔트로피가 0이 되는 상태가 됩니다!
데이터가 완전 순결한 상태라는 거죠 ㅋ
하지만 Full tree가 절대 Best tree는 아니라는 점입니다.
분류가 될수록 그 결과는
High variance & Low bias 특징을
갖기 때문이기도 합니다.
(과적합 된 나무라고 한다네요..)
의사결정나무 모델 학습의 또 다른 축인
가지치기(pruning)이라고 또 있는데요..
여기서부터는 다..다음에
다..다뤄보도록 할게요!

지금까지 솬씨티였습니다!
아직 많이 초보티도 나고
어설프지만 정상의 기발자가 될 때까지..! ^_^
'Business > IT Knowledge' 카테고리의 다른 글
| [Ad Tech] 세계 10위권의 Ad Exchange 社, Index Exchange 분석 (6) | 2020.03.16 |
|---|---|
| [ML] 밑바닥부터 시작하는 머신러닝 Chapter 1-2 (2) | 2020.03.10 |
| [ML] 밑바닥부터 시작하는 머신러닝 Chapter1_1 - Introduction to ML (0) | 2020.03.05 |
| YouTube의 Ad sequencing을 이용해 재도약한 Airbnb (0) | 2020.03.04 |
| [Ad Tech] AD Mediation의 역할 in 온라인 광고 시장 (2) | 2020.02.19 |




댓글